
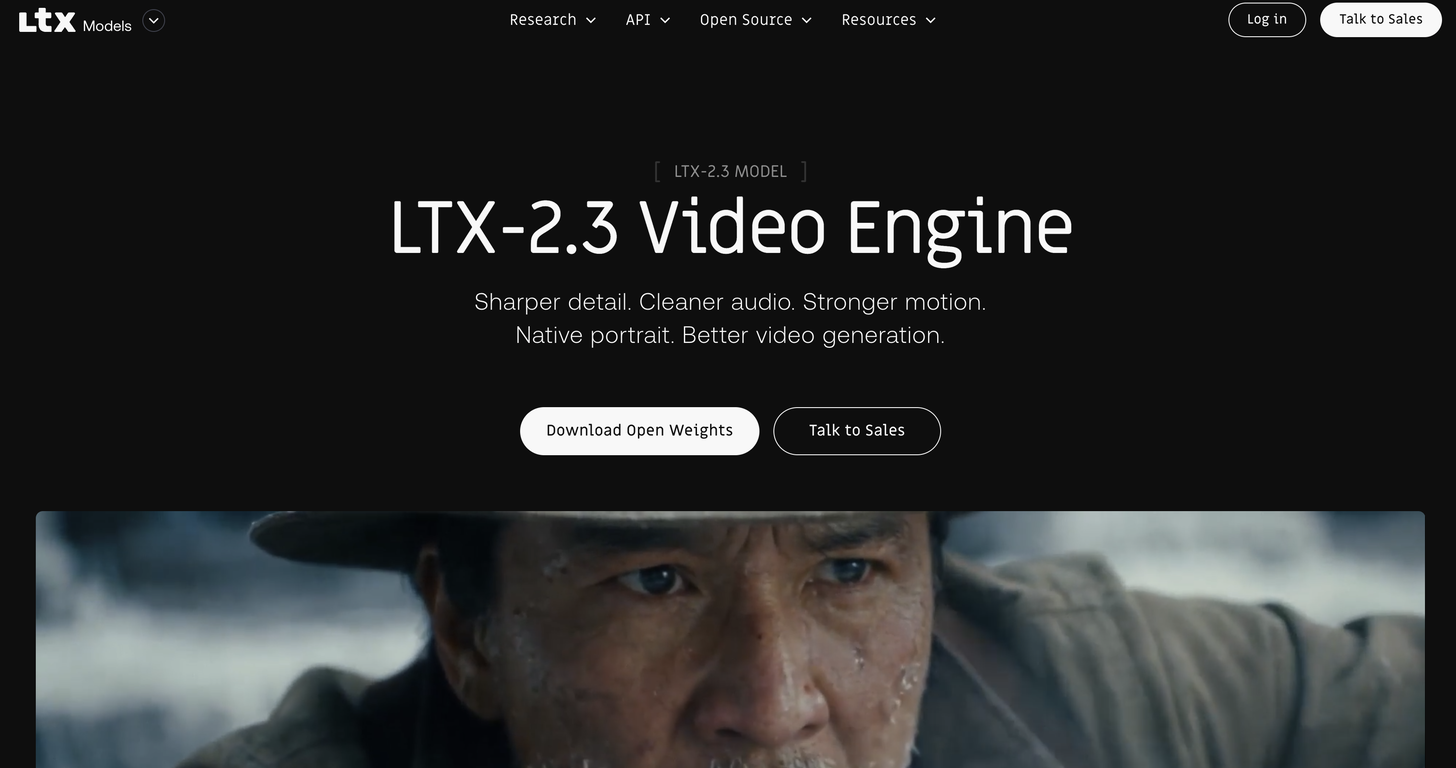
LTX by Lightricksv2.3Version updatev2.3Mar 5, 2026Sharper fine details via a rebuilt latent space and updated VAE, improving textures and edge fidelity.
Better prompt understanding from a larger, upgraded text connector, reducing drift on complex prompts.
Stronger image-to-video motion with fewer frozen clips, less “Ken Burns” panning, fewer unexpected cuts, and better consistency.
Cleaner, more reliable audio from dataset filtering plus a new vocoder, with tighter alignment and fewer artifacts.
Native portrait video support up to 1080x1920, trained for vertical instead of cropped landscape.
Overview
LTX-2 is an open-source, next-generation multimodal AI model designed for video with synchronized audio and image creation as a comprehensive solution for creative workflows.
Capable of running on consumer-grade GPUs, it combines high-fidelity visuals, coherent sound, and multi-flow performance modes into a single platform.
LTX-2 has the capability to generate, enhance, and repurpose visuals more efficiently. Unlike most models, it considers sound and visuals in a unified production process for synchronized motion, dialogue, ambience, and music.
The model is designed to work with real production workflows, connecting directly with editing suites, broadcast tools, game engines, and VFX pipelines.
It supports both quick previews and delivery-ready 4K outputs. The model provides creative control through text, image, depth, and reference-video inputs, and offers multi-keyframe conditioning, 3D camera logic, and fine-tuning options.
As an open-source tool, LTX-2 enables researchers, enterprises, and independent creators to customize the model to fit their needs. Its use cases include post-production, pre-production, animation, restoration among others, offering solutions to automate motion tracking, rotoscoping, plate replacement, and other tasks, thereby reducing the time and cost of production while maintaining quality.
The upcoming releases will offer open access to the model's weights and training code. Its flexibility and customization options make it ideal for studios, research teams, and solo developers.
Supported features
Releases
Sharper fine details via a rebuilt latent space and updated VAE, improving textures and edge fidelity.
Better prompt understanding from a larger, upgraded text connector, reducing drift on complex prompts.
Stronger image-to-video motion with fewer frozen clips, less “Ken Burns” panning, fewer unexpected cuts, and better consistency.
Cleaner, more reliable audio from dataset filtering plus a new vocoder, with tighter alignment and fewer artifacts.
Native portrait video support up to 1080x1920, trained for vertical instead of cropped landscape.

Pricing
Other tools by Lightricks
-
 Michael McWilliam🛠️ 1 tool 🙏 5 karmaOct 7, 2025@PhotoleapI think this is the point of a free trial...
Michael McWilliam🛠️ 1 tool 🙏 5 karmaOct 7, 2025@PhotoleapI think this is the point of a free trial... -

Top alternatives
-
 Turn Music & Ideas into Viral Videos In One Click
Turn Music & Ideas into Viral Videos In One Click -
 Create AI-generated videos with easeWE USE D-ID AT THE COLORADO VIRTUAL CREATIVE FACTORY...AND LOVE IT.
Create AI-generated videos with easeWE USE D-ID AT THE COLORADO VIRTUAL CREATIVE FACTORY...AND LOVE IT. -
 Transform text into captivating videos instantly.You get 300 credits upon signing up, which is enough to test out the app and see its potential. I had a bit of fun with it. It takes a few minutes to generate content, but the results are impressive. There are many styles, modifiers, and customization options available. I would definitely use this for content creation or storytelling.
Transform text into captivating videos instantly.You get 300 credits upon signing up, which is enough to test out the app and see its potential. I had a bit of fun with it. It takes a few minutes to generate content, but the results are impressive. There are many styles, modifiers, and customization options available. I would definitely use this for content creation or storytelling. -
 Create AI spokesperson videos from text
Create AI spokesperson videos from text -
 AI Video GenerationThey're dreaming if they think I'd give them my credit card info just for a free trial. Most useless thing ever...
AI Video GenerationThey're dreaming if they think I'd give them my credit card info just for a free trial. Most useless thing ever... -
 Multi-shot video generation from text and image.
Multi-shot video generation from text and image.










