
A Simple Baseline for Streaming Video Understanding
A simple video streaming baseline that outperforms SOTAs.
README
![]()
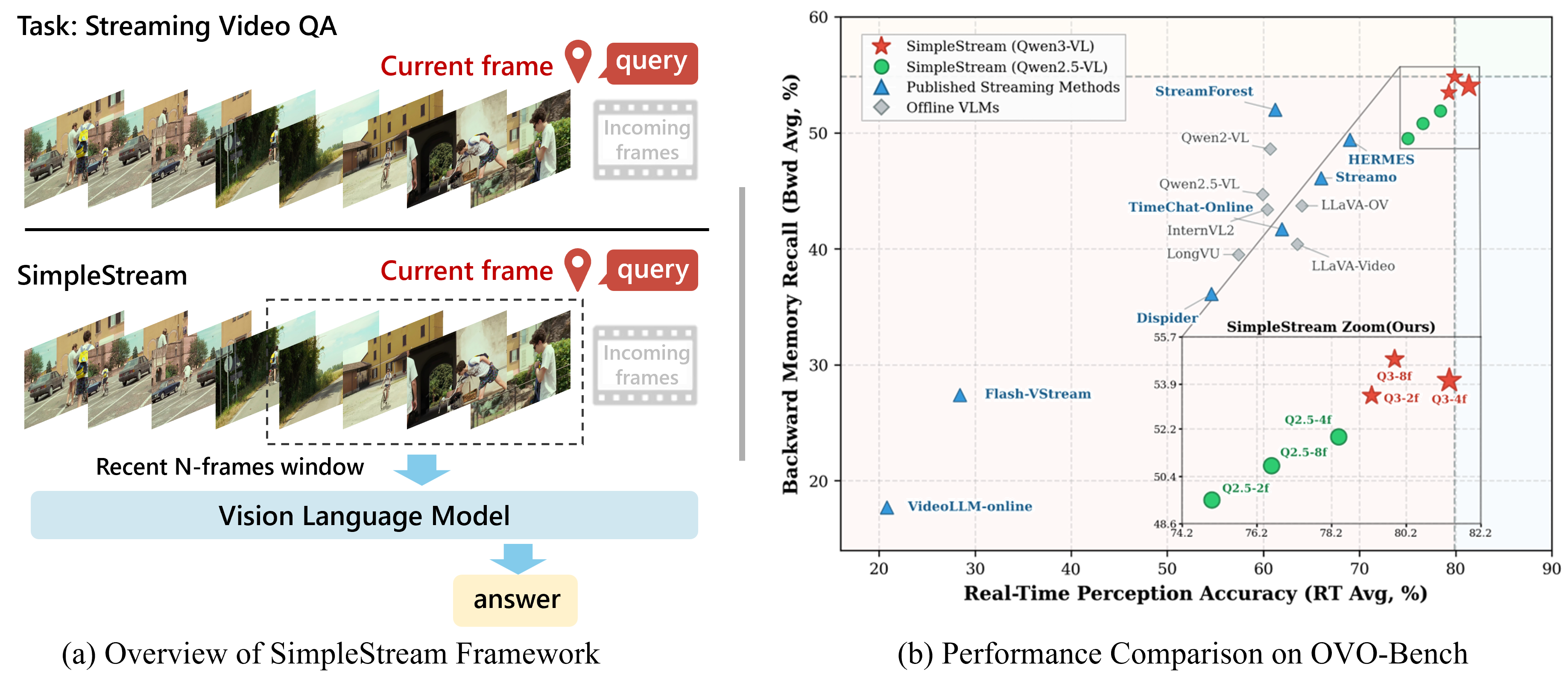 A sliding-window baseline that feeds only the most recent ***N*** frames to an off-the-shelf VLM **matches or surpasses** published streaming video understanding models. No memory bank, no retrieval, no compression.
A sliding-window baseline that feeds only the most recent ***N*** frames to an off-the-shelf VLM **matches or surpasses** published streaming video understanding models. No memory bank, no retrieval, no compression.
🚀 News
📄 [2026/04] SimpleStream paper is released.
💻 [2026/04] Code and evaluation scripts are open-sourced.
✨ Highlights
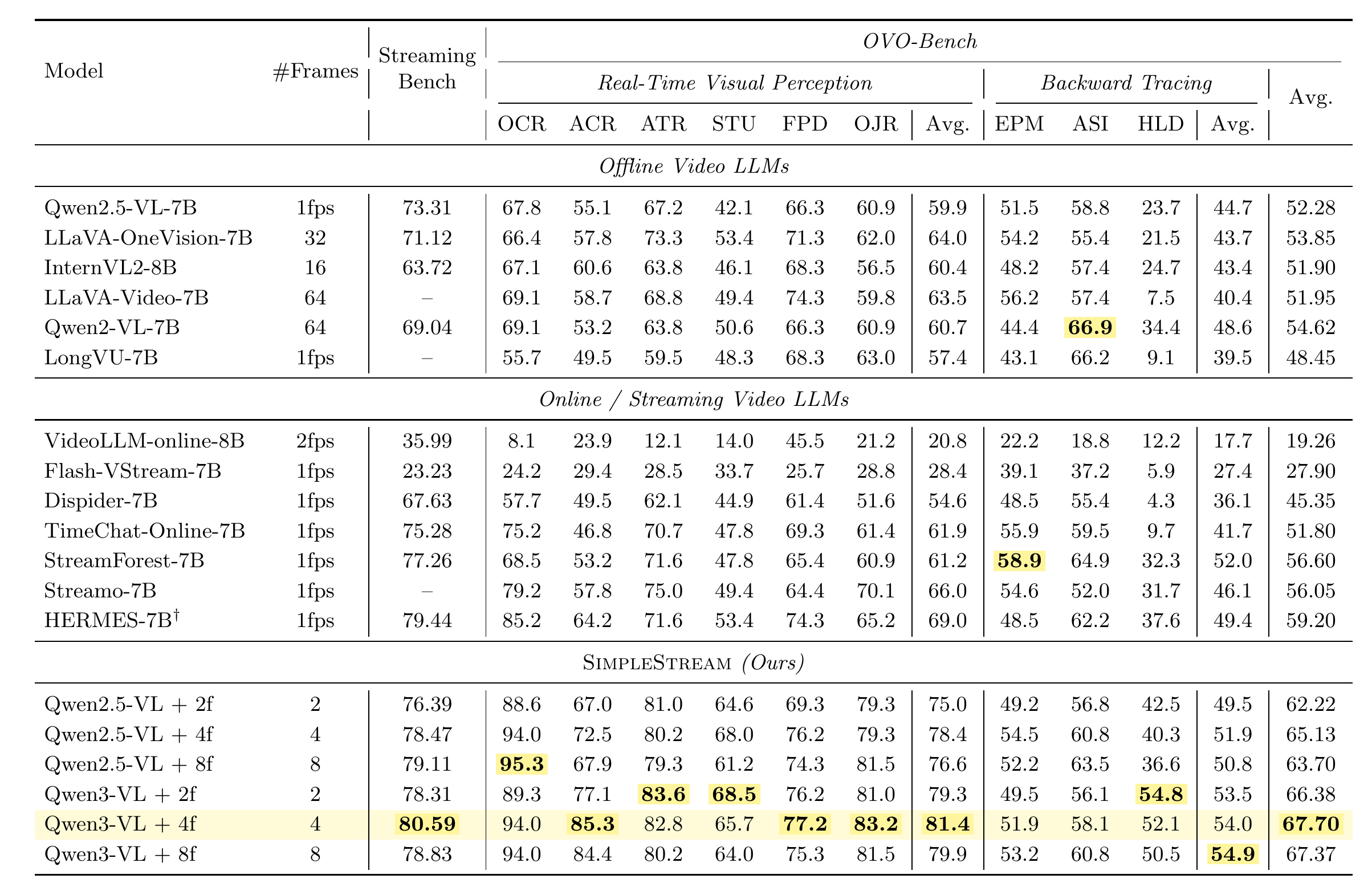
- Simple yet strong. With only 4 recent frames, SimpleStream reaches 67.7% on OVO-Bench and 80.59% on StreamingBench, surpassing all published streaming methods.
- Perception-memory trade-off. Adding historical context improves recall but consistently degrades real-time perception, which dominates aggregate scores.
- Training-free. SimpleStream uses off-the-shelf VLMs (Qwen2.5-VL, Qwen3-VL) with zero fine-tuning.
📊 Main Results
🛠️ Getting Started
Environment Setup
conda create -n simplestream python=3.10 -y
conda activate simplestream
pip install -r requirements.txt
# Optional: faster attention backend
pip install flash-attn --no-build-isolationModels
Downloaded automatically from HuggingFace on first run:
Qwen/Qwen3-VL-8B-Instruct(primary)Qwen/Qwen2.5-VL-7B-Instruct(cross-validation)
Data Preparation
- OVO-Bench: Download from OVO-Bench. Place annotations at
data/ovo_bench/ovo_bench_new.jsonand chunked videos atdata/ovo_bench/chunked_videos/. - StreamingBench: Download from StreamingBench. Place questions at
data/streamingbench/questions_real.jsonand videos atdata/streamingbench/videos/.
🧪 Experiments
<details>
<summary><b>Qwen3-VL on OVO-Bench</b></summary>
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --num_processes=2 \
main_experiments/eval_qwen3vl_ovo.py \
--model_path Qwen/Qwen3-VL-8B-Instruct \
--anno_path data/ovo_bench/ovo_bench_new.json \
--chunked_dir data/ovo_bench/chunked_videos \
--result_dir main_experiments/results/ovo_qwen3vl_recent8 \
--recent_frames_only 8 \
--chunk_duration 1.0 \
--fps 1.0Or use the convenience launcher for 4-GPU:
bash main_experiments/run_qwen3vl_ovo_4gpu.sh</details>
<details>
<summary><b>Qwen2.5-VL on OVO-Bench</b></summary>
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --num_processes=2 \
main_experiments/eval_qwen25vl_ovo.py \
--model_path Qwen/Qwen2.5-VL-7B-Instruct \
--anno_path data/ovo_bench/ovo_bench_new.json \
--chunked_dir data/ovo_bench/chunked_videos \
--result_dir main_experiments/results/ovo_qwen25vl_recent8 \
--recent_frames_only 8 \
--chunk_duration 1.0 \
--fps 1.0</details>
<details>
<summary><b>StreamingBench</b></summary>
--top-k 0 disables retrieval and keeps only the most recent chunks.
CUDA_VISIBLE_DEVICES=0 python main_experiments/eval_streamingbench.py \
--anno-path data/streamingbench/questions_real.json \
--video-dir data/streamingbench/videos \
--top-k 0 \
--recent-frames-only 4 \
--chunk-duration 1.0 \
--fps 1.0 \
--output-dir main_experiments/results/streamingbench_recent4</details>
<details>
<summary><b>Efficiency Benchmark</b></summary>
Measures TTFT, throughput, and memory from a user-provided source video.
CUDA_VISIBLE_DEVICES=0 python efficiency/eval_efficiency.py \
--source-video /path/to/your/source_video.mp4 \
--model-name Qwen/Qwen2.5-VL-7B-Instruct \
--chunk-size 8 \
--recent-frames 4</details>
<details>
<summary><b>Scoring</b></summary>
python scoring/score_ovo_bench.py \
--result_path main_experiments/results/ovo_qwen3vl_recent8/qwen3vl_results_*.json</details>
📢 Citation
If you find this work useful, please consider citing our paper:
@article{simplestream2026,
title={A Simple Baseline for Streaming Video Understanding},
author={Shen, Yujiao and Tian, Shulin and Yang, Jingkang and Liu, Ziwei},
journal={arXiv preprint arXiv:2604.02317},
year={2026}
}🙏 Acknowledgement
- Qwen-VL: the VLM backbone used in our experiments.
- OVO-Bench and StreamingBench: the evaluation benchmarks.





