What is ImageBind by Meta?
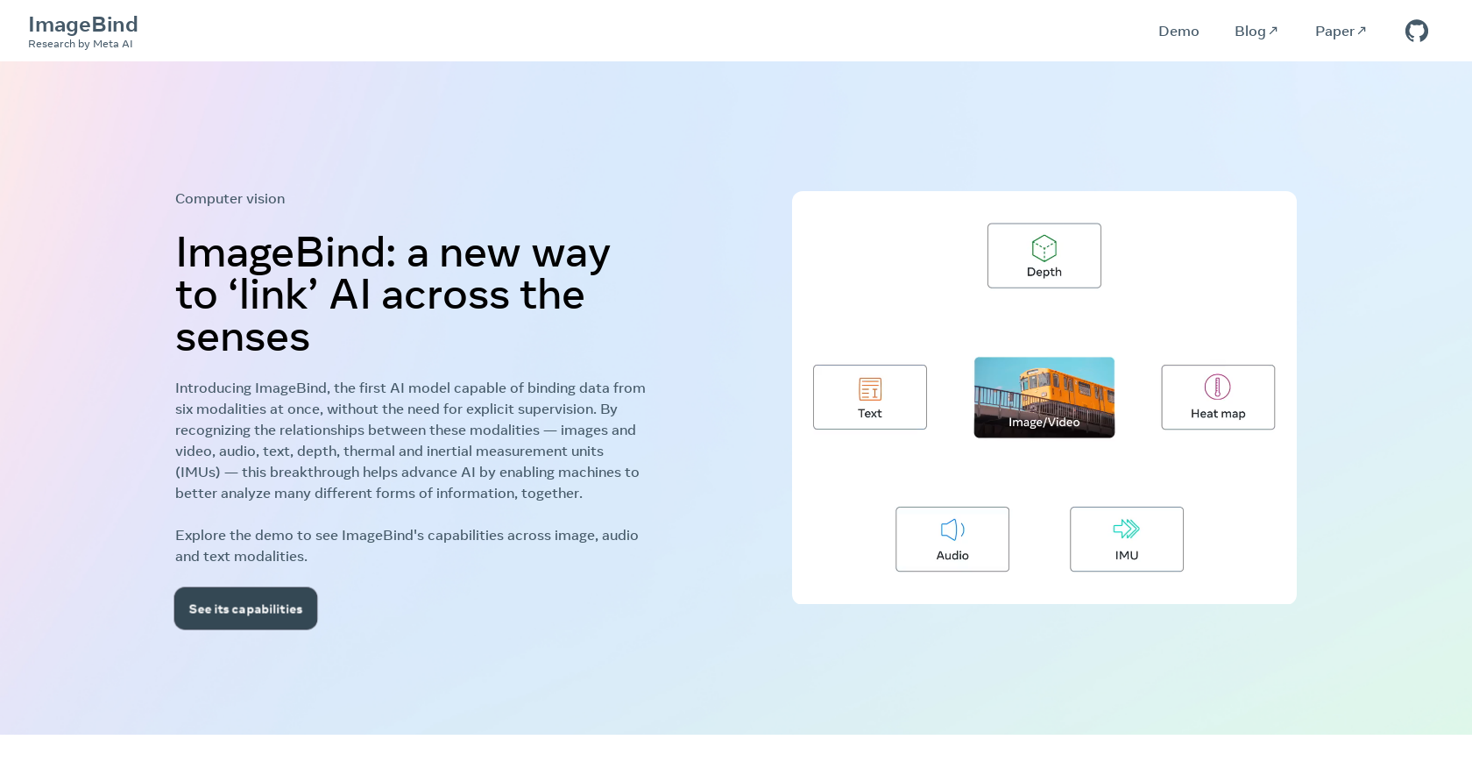
ImageBind by Meta is a state-of-the-art AI model that binds data from six different modalities simultaneously. It recognizes the relationships between these modalities, enabling machines to analyze various forms of information collaboratively. ImageBind achieves this feat without the need for explicit supervision, marking it as the first of its kind.
How does ImageBind work?
ImageBind works by learning a single embedding space that binds multiple sensory inputs together. It recognizes the relationships between different modalities such as images and video, audio, text, depth, thermal, and inertial measurement units (IMUs). It upgrades existing AI models to handle multiple sensory inputs, enhancing their recognition performance on zero-shot and few-shot recognition tasks across modalities.
What are the six modalities that ImageBind can bind at once?
The six modalities that ImageBind can bind at once are images and video, audio, text, depth, thermal, and inertial measurement units (IMUs).
Why is ImageBind considered a breakthrough?
ImageBind is considered a breakthrough because it is the first AI model that is capable of binding data from six modalities at once without the need for explicit supervision. It can upgrade existing AI models to support input from any of the six modalities while improving their performance in zero-shot and few-shot recognition tasks.
Can ImageBind enhance the capability of other AI models?
Yes, ImageBind can enhance the capability of other AI models. It upgrades existing AI models to support input from any of the six modalities, which in turn boosts their recognition performance on zero-shot and few-shot recognition tasks across modalities.
What kinds of tasks can ImageBind improve performance on?
ImageBind can improve performance on a variety of tasks, notably in zero-shot and few-shot recognition tasks across modalities. It achieves this by binding multiple sensory inputs and supporting audio-based search, cross-modal search, multimodal arithmetic, and cross-modal generation.
How does ImageBind handle multiple sensory inputs?
ImageBind handles multiple sensory inputs by learning a single embedding space that binds these inputs together. This allows it to recognize the relationships between images and video, audio, text, depth, thermal, and IMUs, thereby augmenting its analysis and recognition abilities.
Is ImageBind open source?
Yes, ImageBind is open source. This allows developers to freely use and integrate ImageBind into their applications while abiding by the terms of its license.
What are the licensing terms for ImageBind?
The licensing terms for ImageBind fall under the MIT license, which allows developers worldwide to freely use and integrate the model into their applications as long as they comply with the license.
How does ImageBind relate to machine learning capabilities?
ImageBind significantly enhances machine learning capabilities by enabling collaborative analysis of different forms of information. By binding data from various sensory modalities, it offers a comprehensive, collaborative approach to information analysis rarely seen in AI models.
Can ImageBind support audio-based search?
Yes, ImageBind supports audio-based search. This is achieved by its ability to bind and process audio data, along with other modalities, offering a multidimensional approach to data analysis.
What is meant by cross-modal search in ImageBind?
Cross-modal search in ImageBind refers to the model's ability to search data across different modalities collaboratively. That means it can process and relate data from text, images, audio, and other sensory inputs in a single search.
How does ImageBind achieve multimodal arithmetic?
ImageBind achieves multimodal arithmetic by processing and relating information from multiple sensory inputs. This capability allows it to compute and cognize relationships between modalities, thereby performing tasks that require analysis across multiple types of data.
Can ImageBind do cross-modal generation?
Yes, ImageBind can do cross-modal generation. This means the model can generate outputs based on the relationships it recognizes between multiple sensory inputs, such as images, audio, and text.
What is emergent recognition performance in ImageBind?
Emergent recognition performance in ImageBind refers to its enhanced ability to recognize features and relationships across different sensory modalities without requiring explicit training for each. It is particularly proficient in emergent zero-shot and few-shot recognition tasks across modalities.
What is meant by zero-shot and few-shot recognition tasks in ImageBind?
Zero-shot and few-shot recognition tasks refer to situations where the AI model must recognize or classify objects or data it has either never seen before (zero-shot) or has only seen a few times (few-shot). ImageBind excels in these tasks due to its ability to bind and analyze multiple types of data collaboratively.
Does ImageBind perform better than specialist models explicitly trained for specific modalities?
Yes, ImageBind has been noted to perform better than prior specialist models explicitly trained for specific modalities. Even in emergent zero-shot recognition tasks across modalities, ImageBind outperforms specialist models.
What is meant by explicit supervision and how ImageBind achieves its tasks without it?
Explicit supervision refers to the manual human intervention required to train an AI model, guiding it towards expected outputs for given inputs. ImageBind, however, achieves its tasks without explicit supervision, meaning it has learned to process and relate data from different modalities without needing specific instruction to do so.
How do developers integrate ImageBind into their applications?
Developers can integrate ImageBind into their applications by accessing its open-source code under the MIT license. They can then make use of the features and capabilities of ImageBind as per the needs of their applications.
Can I see the demo of ImageBind's capabilities?
Yes, a demo showcasing the capabilities of ImageBind across image, audio, and text modalities can be accessed on their website.