What is MusicLM?
MusicLM is a unique project by Google that represents music in terms of text. Moods, instruments, characteristics, and other aspects of music are converted into natural language descriptions.
What is the purpose of MusicLM?
MusicLM is developed to provide creative and technological solutions in the realm of music and AI. The objective is to label music with descriptive text, allowing better accessibility and understanding of different aspects of a musical piece.
What kind of data does MusicLM provide?
MusicLM provides data in the form of music clips labeled with an aspect list and a free-text caption. An aspect list is a series of adjectives describing the music, while the free-text caption provides a more detailed description of the music including the mood and the instruments used.
What is the size of the MusicCaps dataset?
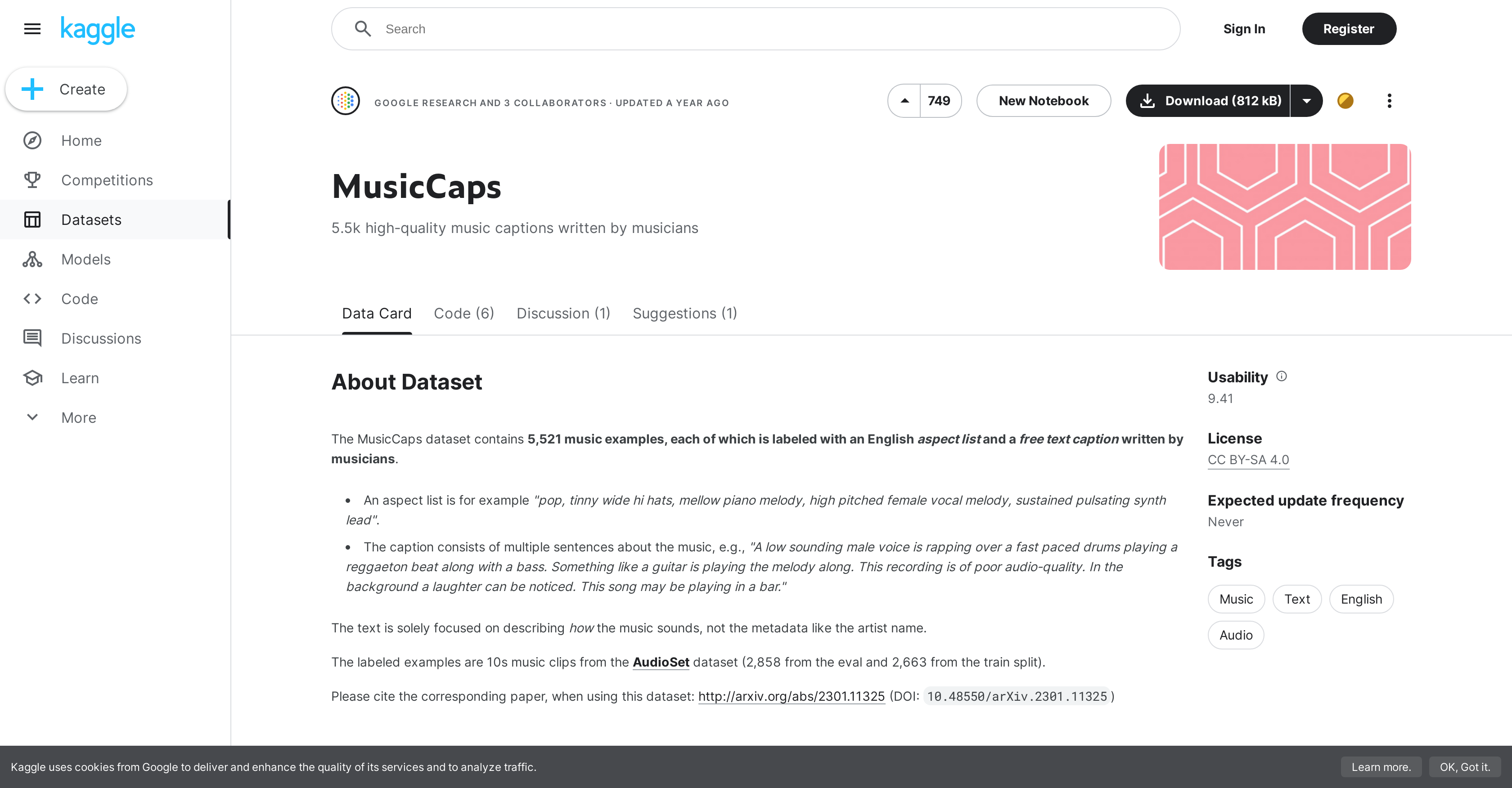
The MusicCaps dataset, part of the MusicLM project, contains 5,521 music clips, each 10 seconds long and labeled with an English aspect list and a free-text caption written by musicians.
What adjectives describe the music in the aspect list of MusicLM?
The aspect list in MusicLM uses a variety of adjectives to describe the music, such as 'pop', 'sustained', 'pulsating', 'tinny', 'mellow', and 'high-pitched' among others.
What is the eval and train split in MusicLM?
In MusicLM, the eval and train split is a form of data segregation where the dataset containing music clips is split into two parts - an evaluation (eval) part and a training (train) part.
What type of license does MusicLM use?
MusicLM uses a Creative Commons BY-SA 4.0 license.
What metadata is included with each music clip in MusicLM?
In MusicLM, each music clip is labeled with metadata including YT ID, start and end positions in the video, labels from the AudioSet dataset, aspect list, caption. It also includes author ID for grouping samples by who wrote them, and details on whether it is part of a balanced subset, or the AudioSet eval split.
What is the intended use of the MusicLM dataset?
The intended use of the MusicLM dataset is for music description tasks.
What type of tasks is the MusicLM dataset suitable for?
The MusicLM dataset is suitable for variety of tasks such as music recommendation, automatic playlist creation, and in assisting music curators.
How can I access the MusicCaps dataset?
Access to the MusicCaps dataset is provided through the Kaggle platform. It can be viewed directly on Kaggle's website or downloaded for offline use.
What does a free-text caption in MusicLM describe?
In MusicLM, a free-text caption provides a detailed description of how the music sounds. It includes in-depth details of the music such as instruments used and the mood of the music.
What is the source of the audio data for MusicCaps?
MusicCaps dataset, a part of MusicLM, sources its audio data from the AudioSet dataset.
What does the YT ID metadata refer to in MusicLM?
In MusicLM, the YT ID metadata points to the YouTube video in which the corresponding labeled music segment appears.
Can I use MusicLM for commercial purposes?
As MusicLM is licensed under Creative Commons BY-SA 4.0, it can be used for both non-commercial and commercial purposes provided the terms and conditions are complied with.
Is it possible to sort or filter the music clips by who wrote them in MusicLM?
Yes, the MusicLM system includes the author ID as a part of the metadata for each music clip. This allows for grouping and sorting samples based on who wrote them.
Is the MusicCaps dataset updated regularly?
The MusicCaps dataset does not expect regular updates, it's mentioned that update frequency is 'never'.
What was the method for curating and labeling the music clips in MusicLM?
The music clips in MusicLM are sourced from the AudioSet dataset. These clips are then labeled with an aspect list and a free-text caption written by musicians to describe various aspects of the music.
What is the AudioSet eval split in MusicLM?
In MusicLM, the AudioSet eval split indicates whether the clip is from the AudioSet eval split. It is used to classify the data for training and evaluation purposes.
How can MusicLM help in music description tasks?
MusicLM, with its unique approach to representing music as text descriptions, can be valuable in music description tasks. It can help in creating more accurate and efficient music recommendation systems, and potentially improve accessibility for people with hearing impairments by providing textual descriptions of musical pieces.
 15,299
15,299