What is Story Diffusion Gen?
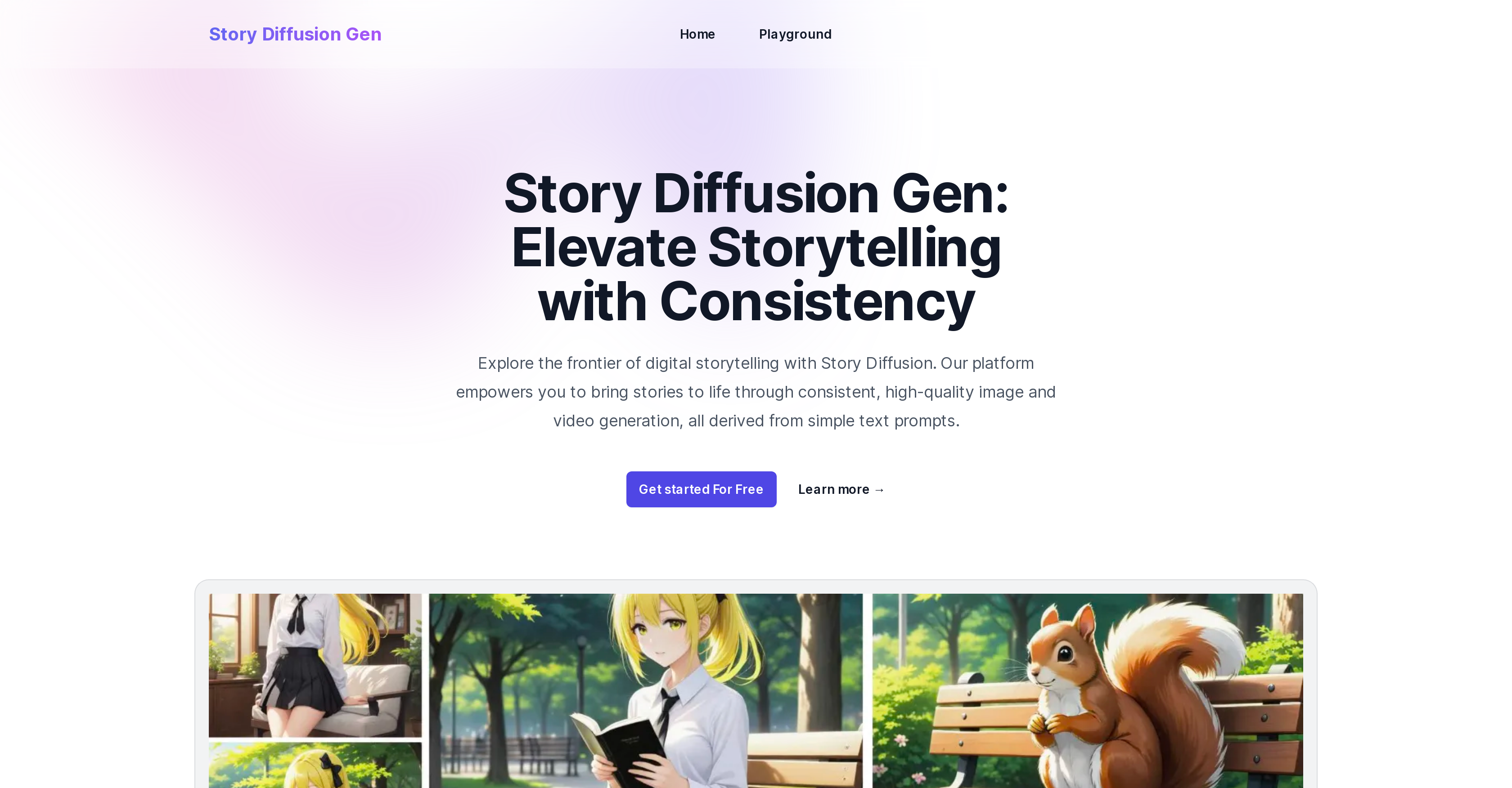
Story Diffusion Gen is an advanced AI platform designed for digital content creation, particularly for storytelling. It generates consistent, high-quality images and videos from text prompts, transforming them into visual narratives. It caters to creators of varying skill levels, enabling them to produce professional-grade digital content.
How does Story Diffusion Gen generate images from text prompts?
Story Diffusion Gen employs a consistent self-attention mechanism to generate images from text prompts. Users begin by preparing detailed text prompts, providing key elements of the story and desired visual outcomes. This mechanism then generates character-consistent images that follow the narrative's direction.
Can Story Diffusion Gen generate videos?
Yes, Story Diffusion Gen can generate videos. Its unique feature, known as the motion predictor, transitions between the generated images to create dynamic and seamless videos.
What is the self-attention mechanism in Story Diffusion Gen?
The self-attention mechanism in Story Diffusion Gen is employed to maintain consistency in character and scene across images and videos. It ensures the produced visuals align coherently with the narrative, based on text prompts from the user.
Can I create a comic strip using Story Diffusion Gen?
Yes, you can create a comic strip using Story Diffusion Gen. The program offers tools specifically for creating high-quality comics, allowing users to combine generated images into comics and utilize layout arrangement tools to ensure a consistent narrative flow.
How would I go about sharing my creations from Story Diffusion Gen?
Upon completing the creation process in Story Diffusion Gen, the platform allows users to share their creations by exporting the stories, comics, or videos. This feature empowers users to showcase their unique vision and creativity to the world.
Are multiple text prompts allowed in Story Diffusion Gen?
Yes, multiple text prompts are allowed in Story Diffusion Gen. In fact, for more complex stories, the use of multiple text prompts can help achieve better layout and continuity in the narrative.
How user-friendly is Story Diffusion Gen's interface?
The interface of Story Diffusion Gen has been designed to be user-friendly. Creators of all skill levels can easily access the technology to produce professional-grade digital content. The platform aims to provide an easy-to-navigate user interface making it accessible to a vast range of creators.
What are the key features of Story Diffusion Gen?
Story Diffusion Gen comes with key features such as consistent image generation, long-range video generation via a motion predictor, high-quality comics creation, and a user-friendly interface. All features are designed to elevate storytelling by ensuring visual continuity in generated images and videos.
How consistent is the image generation in Story Diffusion Gen?
The image generation in Story Diffusion Gen is quite consistent. This consistency is achieved through the platform's self-attention mechanism, which maintains character and scene consistency across images and videos, enhancing the storytelling experience with visual continuity.
What is the motion predictor feature in Story Diffusion Gen?
The motion predictor feature in Story Diffusion Gen extends the storytelling capability by generating videos from sequences of condition images. This feature offers larger motion prediction for dynamic narratives, allowing for seamless transition between images, hence creating engaging videos.
Can Story Diffusion Gen maintain narrative continuity with multiple text prompts?
Yes, Story Diffusion Gen can maintain narrative continuity with multiple text prompts. The consistent self-attention mechanism ensures a coherent storytelling experience, even in more complex stories where multiple prompts are used.
How do I use Story Diffusion Gen to create high-quality comics?
To create high-quality comics with Story Diffusion Gen, you would need to combine the generated images into comics using the provided tools for layout arrangement and storytelling flow. This allows for the creation of compelling comics with consistent visuals and narrative continuity.
What are the steps to create videos using Story Diffusion Gen?
The steps to create videos using Story Diffusion Gen are quite straightforward. First, prepare text prompts that outline the story's key elements. Generate images using the consistent self-attention mechanism. Finally, extend your storytelling to videos by transitioning between the generated images with the motion predictor. This brings dynamic motion to your narrative.
How do I ensure storytelling flow in my creations with Story Diffusion Gen?
Ensuring storytelling flow in your creations with Story Diffusion Gen involves using detailed and clear text prompts that outline your story's key elements. Also, for visually complex stories, leveraging multiple text prompts will ensure better layout and continuity in your narrative.
Can I export the stories I create using Story Diffusion Gen?
Yes, you can export the stories you create using Story Diffusion Gen. The platform allows users to export their stories, comics, and videos so they can share their creations with the world.
Does Story Diffusion Gen offer any layout arrangement tools for comics creation?
Yes, Story Diffusion Gen offers layout arrangement tools specifically designed for comics creation. This feature, in conjunction with the platform's ability to generate consistent images, allows users to produce well-structured and high-quality comics.
Is the storytelling feature of Story Diffusion Gen suitable for complex stories?
Yes, the storytelling feature of Story Diffusion Gen is certainly suitable for complex stories. The consistent self-attention mechanism, combined with the ability to use multiple text prompts, allows for better continuity and coherence in complex visual narratives.
Can Story Diffusion Gen generate both images and videos from the same text prompts?
Yes, Story Diffusion Gen can generate both images and videos from the same text prompts. The self-attention mechanism generates images based on the narrative outlined in the text prompts, while the motion predictor creates videos by transitioning between these generated images.
How do I start creating visual narratives with Story Diffusion Gen?
To create visual narratives with Story Diffusion Gen, start by preparing engaging text prompts outlining your story's key elements and desired visual outcomes. Let the self-attention mechanism generate character-consistent images based on these prompts. You can further extend your creativity to generate videos or combine images into a comic strip. Now, you can export and share your created visual narratives.
 14,919
14,919