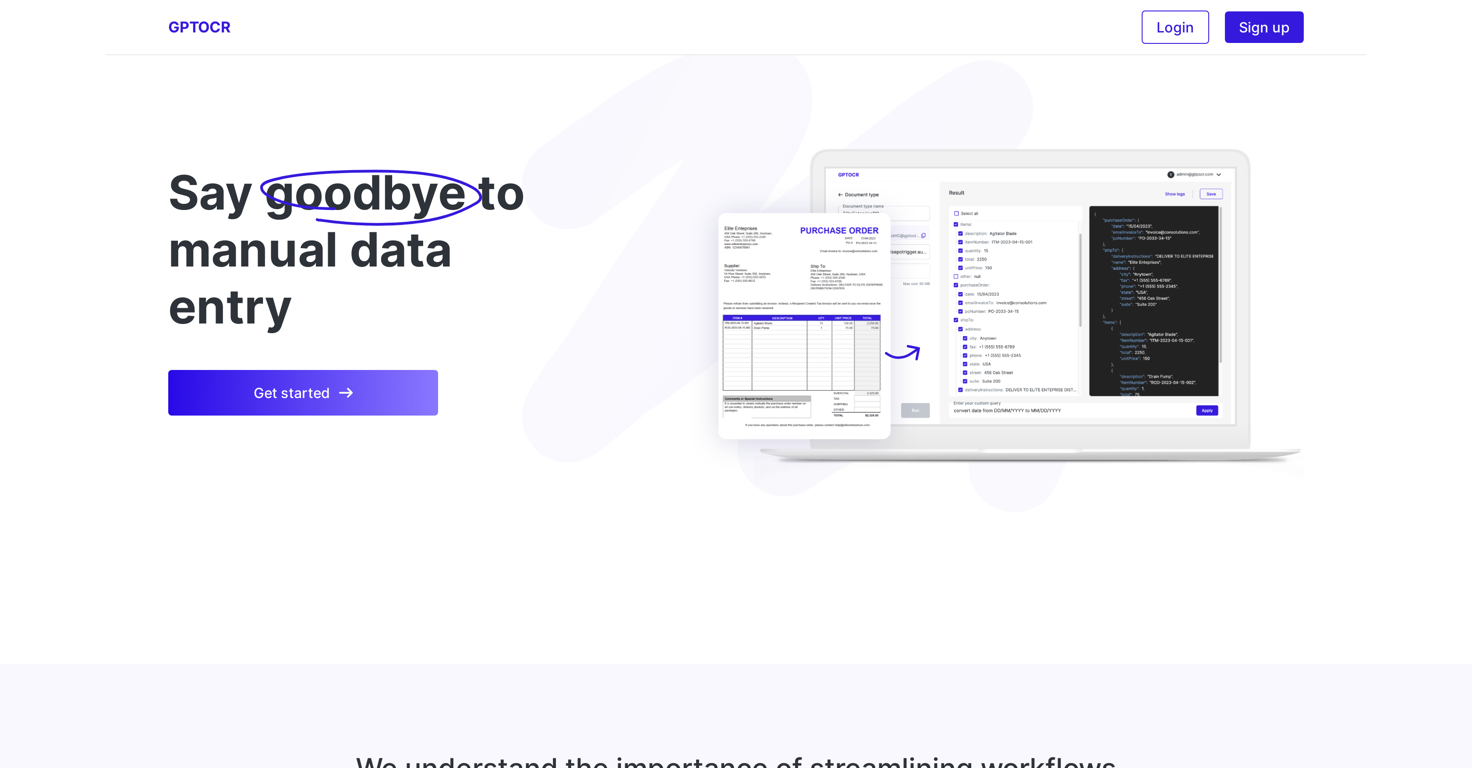
What exactly is GPTOCR?
GPTOCR is an AI-based tool that works to make data extraction from PDF documents effortless and minimizes time-consuming manual data entry. It transforms documents into structured JSON files that are ready to use, saving businesses time and money, and reducing the risk of human errors.
How does GPTOCR extract data from PDFs?
The specifics of how GPTOCR extracts data from PDFs may not be explicitly mentioned. However, as an AI-powered tool, it likely uses machine learning algorithms and natural language processing to identify, analyze, and extract relevant data.
What kind of data can GPTOCR extract?
The type of data that GPTOCR can extract may not be known exactly, but based on its primary function, it's likely capable of extracting numerical and textual information present within PDF documents.
How does GPTOCR transform documents into structured JSON files?
GPTOCR uses its AI capabilities to analyze and extract data from PDFs and then structures this data into JSON files. This is all accomplished through its own inner algorithms and programming, turning manual data into structured, machine-readable format.
What are the benefits of using GPTOCR for businesses?
Using GPTOCR, businesses can save time as it eliminates manual data entry and formatting tasks. They also reduce the risk of human errors in data entry, ensuring consistency and accuracy. It also improves efficiency by enabling the team to focus on high-value tasks and projects and enhances collaboration through standardized, structured data format.
How does GPTOCR reduce human error in data entry?
GPTOCR operates autonomously, reducing human involvement in error-prone tasks such as data entry. By relying on its machine learning algorithm, it ensures accurate and consistent data extraction from documents, thus minimizing human error.
In which ways can GPTOCR enhance team collaboration?
GPTOCR enhances team collaboration by providing structured data in a standardized format. This relieves team members from having to navigate and reformat unstructured data, allowing them to work together more efficiently and effectively.
How does GPTOCR improve efficiency?
GPTOCR improves efficiency by automating the labor-intensive process of document parsing and data entry. This allows team members to focus on higher-value tasks rather than copy-pasting or retyping data from documents.
What is the process to get in touch with the GPTOCR team?
To get in touch with the GPTOCR team, users can enter their email address on their website. The team will then send an email to learn more about the user’s needs and explain how they can help.
How does GPTOCR ensure the confidentiality and security of user data?
GPTOCR ensures user data confidentiality and security through its terms of service and privacy policy. Although the exact measures taken for data security are not spelled out, they are committed to maintaining the confidentiality of user data.
Is GPTOCR a paid tool or does it have a free version?
IDK
How time-consuming is the process of data extraction using GPTOCR?
While the exact time it takes GPTOCR to extract data from PDFs is not specified, the tool is described as a solution to save time, implying that its process is much quicker than manual data entry.
How accurate is the data extracted by GPTOCR?
GPTOCR is designed to provide data that is accurate and consistent every time, reducing the risk of errors associated with manual data entry.
What are the terms of service of GPTOCR?
The precise terms of service for GPTOCR are not provided here. Yet, it's mentioned they have clearly stated terms of service available on their website.
What is the privacy policy of GPTOCR?
The exact privacy policy of GPTOCR is not spelled out here. However, it's stated that a privacy policy is available on their website, ensuring the confidentiality of user data.
Does GPTOCR require any special skills to operate?
IDK
Can GPTOCR handle bulk PDF files for data extraction?
IDK
What format are the output files from GPTOCR?
Extracted data from GPTOCR is stated to be in the structured JSON format, implying the output files are in JSON format.
Can GPTOCR work with encrypted or password protected PDFs?
IDK
Does GPTOCR save or store the data it extracts?
IDK