What is the main purpose of V7?
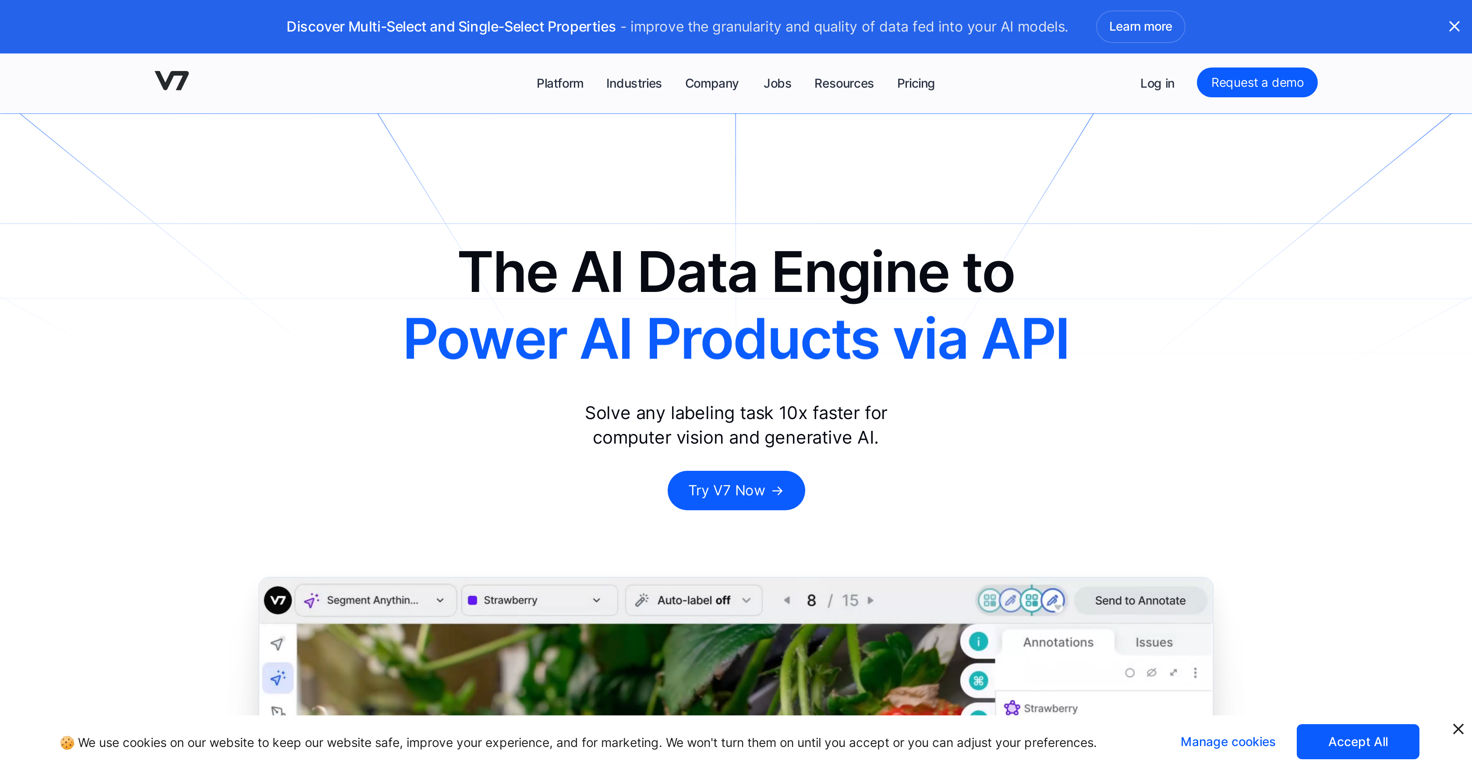
V7 is designed to serve as an AI data engine for computer vision and generative AI applications. The platform aims to provide a full infrastructure for enterprise training data, encompassing aspects such as labeling, workflows, and datasets, it also involves human-in-the-loop training. Through this, V7 caters to improving the quality of data for AI models, dataset management, human-in-the-loop training, and streamlining various tasks.
How does the auto annotation feature of V7 improve data labeling?
V7's auto annotation feature fine-tunes the process of data labeling by automating it, thereby increasing the speed and the accuracy of annotations. This accelerated process is particularly crucial for applications that require large amounts of accurately labeled data, making the task much more manageable and efficient.
What industries can V7 be used in?
V7 can be applied in a range of industries including agriculture, automotive, construction, energy, food & beverage, healthcare, insurance & finance, life sciences & biotech, logistics, manufacturing, retail, software & internet, and sports.
What type of data does V7 support?
V7 supports a broad array of data types. This includes video, image, and text data, giving users the flexibility to use the platform for different kind of projects and tasks.
How does V7's human-in-the-loop training work?
The human-in-the-loop training in V7 involves integrating human intelligence into the process of data labeling and model training. This usually means that while the AI goes through the task of labeling and training, it may flag instances where it is unsure, these instances can then be reviewed and corrected by humans. This form of training is effective in areas where pure automation isn't sufficient and human expertise is required to vet and validate information.
How does the annotation feature of V7 improve the quality of AI models?
V7's annotation feature improves the quality of AI models by allowing users to add multiple annotation properties, resulting in high precision data. This high-quality data in turn results in the development of more accurate and reliable AI models as the models are as good as the data they are trained on.
Can V7 manage datasets and AI models?
Yes, V7 can manage both datasets and AI models. The platform provides dataset management tools to keep all training data in one place, while also offering model management capabilities to automate data workflows. Both these aspects contribute to the efficacy and efficiency of AI model development.
Can annotation tasks in V7 be outsourced?
Yes, annotation tasks in V7 can be outsourced. This allows users to leverage expert labelers to ensure precision and quality in data labeling tasks, freeing them up to focus on other key aspects of their AI model development process.
Does V7 offer any collaboration features?
V7 does provide collaboration features. It enables real-time team annotation, allowing multiple users to work simultaneously on data labeling tasks. This not only speeds up the process but also ensures that all team members carry a unified understanding of the labeling process.
What is V7's AutoAnnotate feature?
V7's AutoAnnotate is an enhanced feature aimed at expediting the process of annotation. Utilizing the AutoAnnotate feature increases both the speed and the accuracy of annotations, in turn providing high-quality data for AI model training.
With which platforms does V7 integrate?
V7 is designed to integrate seamlessly with multiple platforms including AWS, Databricks, and Voxel51. This makes it a highly compatible and versatile tool for a variety of AI data management tasks.
What tools does V7 provide for automating OCR and IDP workflows?
V7 offers a suite of tools designed to automate optical character recognition (OCR) and intelligent document processing (IDP) workflows. These tools simplify and automate the process of extracting, processing, and interpreting data from written or printed text in an image or document, enhancing productivity and eliminating the possibility of human errors.
What types of document can be processed using V7?
V7Ability supports the processing of various types of documents through its intelligent document processing workflows. These tools analyze, recognize, and extract data from documents, automating the processing and making it effective and error-free.
How can V7's platform streamline data workflow?
V7 has a variety of features to streamline a user's data workflow. These include its robust auto annotation, dataset management, model management, and human-in-the-loop training features. Through these functionalities, users can leverage efficient label data, automate data workflows, and oversee the entirety of their data workflow in an intuitive user interface.
Can V7's platform be used for dataset management and model management?
Yes, V7's platform can be used for both dataset management and model management. For dataset management, V7 provides tools that pool together all training data in one easily accessible and manageable location. Furthermore, V7's model management features automate workflows concerning data which translates to greater efficiency and productivity.
Does V7 provide analytics for labeler and model performance?
V7 does provide analytics for labeler and model performance. It tracks aspects like the time spent, the number of annotations created per minute or the total number of labeled images. By providing such insights, V7 helps users gauge and improve the overall performance and efficiency of their model training process.
How does V7 enhance the efficiency of annotation and model training workflows?
V7 enhances the efficiency of annotation and model training workflows by supporting feature-rich, flexible and scalable tools that automate and streamline operations. Automated functionalities like its AutoAnnotate and user-friendly interface boost speed and streamline training, making the overall process more efficient.
How can V7 be used in healthcare industry?
V7 can be leveraged in the healthcare industry by using its DICOM annotation feature for medical imaging. Medical professionals can label and manage intricate medical imaging data effectively. Furthermore, V7's integration with platforms like AWS and Databricks can allow for seamless management and processing of large volumes of healthcare data. It is compliant with major security standards like ISO 27001 which is important in the highly regulated healthcare industry.
What are the data security features of V7?
V7 takes data security seriously. It allows tasks to be assigned to specific labelers limiting what each labeler can see. Moreover, V7 complies with leading security standards like SOC2, HIPAA, and ISO27001, which implies that necessary measures have been taken to ensure the platform is secure and data privacy is protected.
Does V7 provide APIs for easy integration with other tools?
Yes, V7 provides APIs to allow easy integration with other tools. It supports integration with common ML-Ops platforms, deep learning frameworks and cloud storage solutions. This means users can send tasks to other ML-Ops platforms, host data privately in their enterprise cloud storage, and load datasets into their deep learning framework of choice.