What is Vespa?
Vespa is an AI-powered search engine and vector database that allows organizations to apply AI to their big data online. It's an open-source software developed for high performance, scalability, and high availability of search applications.
How does Vespa handle big data analysis?
Vespa manages big data analysis by offering a fully featured search functionality that supports vector search, lexical search, and search in structured data. It employs machine-learned model inference in real-time to analyze data and also handles scalable performance with features to co-locate vectors, metadata, and content on the same item on the same node, running inference there, and scaling this seamlessly across nodes. Its capacity to handle any amount of data and traffic contributes to its capabilities in big data analysis.
What makes Vespa's performance and scalability unique?
Vespa's performance and scalability are unique due to its open-source design and AI-based infrastructure. Built on a C++ core, it provides hardware-near optimizations and efficient utilization of any level of memory and cores. Vespa also scales to any amount of data and traffic, providing unbeatable end-to-end performance. Vespa also automatically manages data distribution over nodes and can redistribute in the background upon any changes.
Is Vespa compatible with all types of search applications?
Yes, Vespa is compatible with all types of search applications. It supports vector search, lexical search, and search in structured data, within the same query. It can be used for several application use cases like search, recommendations, personalization, conversational AI, and semi-structured navigation.
What are the different use cases for Vespa?
Vespa provides a wide range of use cases including search, recommendation and personalization, conversational AI, and semi-structured navigation. For example, Vespa provides structured navigation with superior performance for applications such as e-commerce that use a combination of structured data and text.
Can Vespa manage both vector search and lexical search?
Yes, Vespa can manage both vector search and lexical search. It supports these two along with search in structured data, all in the same query. This empowers users to create production-ready search applications at any scale with any combination of features.
How does Vespa assist with the application development process?
Vespa supports the application development process by simplifying the process of building applications. With Vespa, developers can focus on developing their application while Vespa handles scaling and high availability. The tool also lets developers co-locate vectors, metadata, and content on the same item on the same node, run inference there, and also scale this simultaneously across nodes.
Who are some of the well-known companies that use Vespa?
Several leading companies such as Spotify, Yahoo, and OkCupid use Vespa. For instance, Spotify turned to Vespa for its support for fast Approximate Nearest Neighbor (ANN) search in combination with other application needs.
How does Vespa aid in content personalization and ad targeting?
Vespa aids in content personalization and ad targeting by allowing real-time personalization of content. It enables applications to evaluate recommender models over content items to select the best ones, making it possible to make recommendations specifically for each user or situation using up-to-date information.
What types of machine-learning models does Vespa support?
Vespa supports most machine-learned models from most tools. The tool is engineered around scalable and efficient support for machine-learned model inference, empowering it to make sense of data in real-time.
How does Vespa manage data distribution over nodes?
Vespa automatically manages data distribution over nodes and can redistribute in the background on any changes. This auto-elastic data management relieves users from worrying about how data is divided and distributed.
What is Vespa's capacity in terms of data and traffic?
Vespa scales to any amount of data and traffic. It can serve thousands of queries per second with latency below 100 milliseconds, and runs applications effectively even when serving close to a billion users at a rate of 600,000 queries per second.
How can Vespa be used for recommendation and personalization?
In the context of recommendation and personalization, Vespa evaluates recommender models over content items to select the best ones. The applications built with Vespa can do this online, typically combining fast vector search and filtering with evaluation of machine-learned models over the items. This makes it possible to make recommendations specifically for each user or situation, using completely up-to-date information.
Is Vespa suitable for applications in conversational AI?
Vespa can be used for applications in conversational AI with its ability to store and search vector and text data in real time, and orchestrate many such operations to carry out a task. Vespa integrates these building blocks in a scalable form, making it an ample platform for conversational AI applications.
How does Vespa handle semi-structured navigation?
For applications that use a combination of structured data and text and require structured navigation, Vespa provides features like grouping data dynamically for navigation and filtering, along with search and recommendation. It efficiently caters to semi-structured navigation necessities with great performance, enabling a functionally complete usage leveraging structured data on a unified architecture.
How do Vespa's features contribute to its end-to-end performance?
Vespa's diverse set of features like vector search, lexical search, search in structured data, machine-learned model inference, auto-semantic data management contribute to its unbeatable end-to-end performance. Built on a C++ core, Vespa provides hardware-near optimizations and efficient utilization of memory and cores.
What does the integration of Vespa look like in Spotify's systems?
In Spotify's systems, Vespa enables semantic search using vector embeddings. Spotify turned to Vespa for its support for fast Approximate Nearest Neighbor (ANN) search in combination with other application needs, such as using ranking functions combining vector similarity with other signals.
How does Vespa compare to Elasticsearch in its functionalities?
In terms of functionalities, Vespa offers features not present in Elasticsearch such as seamless scaling of data and traffic, co-location of vectors, metadata, and content on the same item on the same node. Companies such as OkCupid have chosen Vespa over Elasticsearch due to these improved offerings, including Vespa's automatic data management, flexible ranking, and swift addition of new fields for filtering and sorting without needing to refeed all data.
What makes Vespa an ideal solution for real-time recommendations?
Vespa is an ideal solution for real-time recommendations due to its ability to evaluate recommender models over content items to select the best ones. It creates recommendations specific to each user or situation, using the most accurate information. The seamless mix of fast vector search and filtering with evaluation of machine-learned models over the items fuels this real-time recommendation capability.
Are there any resources available for getting started with Vespa?
Yes, multiple resources are available for getting started with Vespa. The Vespa documentation, available at 'docs.vespa.ai', provides an extensive guide to understand Vespa's capabilities. The 'Getting Started' guide on their website provides a step-by-step process to initiate work with Vespa. One can also join the Vespa community on Slack or discover more through its open source project on Github. The Vespa Cloud, available for free use, is another resource to practice with Vespa's features.
 8515
8515 6621
6621 2491
2491 2035
2035 1793
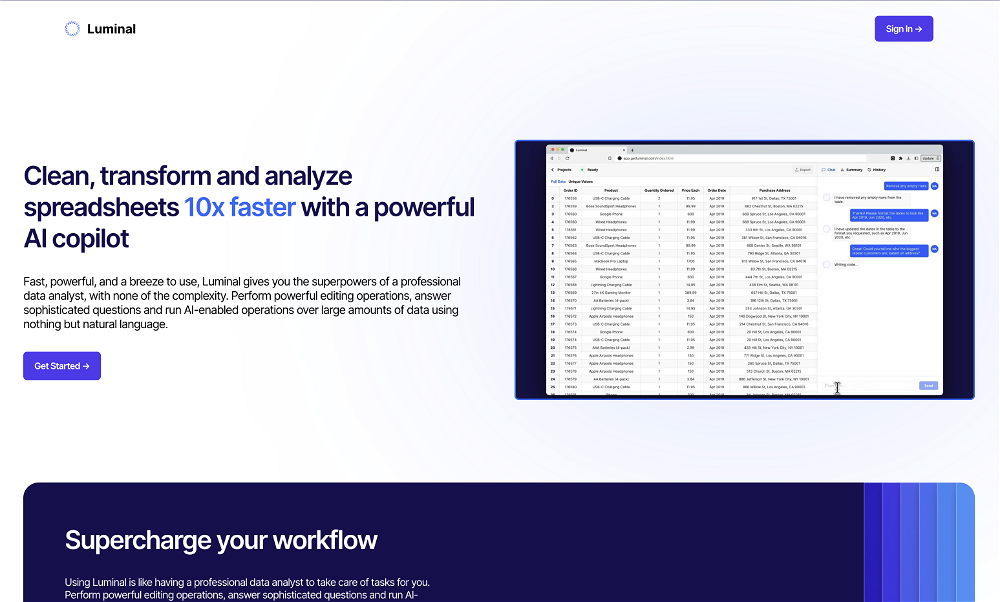
1793 Clean, transform and analyze spreadsheets 10x faster with a powerful AI copilot1222
Clean, transform and analyze spreadsheets 10x faster with a powerful AI copilot1222 104
104 1021
1021 85
85 73
73 72
72 71
71 686
686 664
664 66
66 64
64 602
602 591
591 53
53 53
53 53
53 53
53 501
501 48
48 40
40 35
35 35
35 33
33 311
311 28
28 281
281 28
28 282
282 27
27 27
27 27
27 27
27 27
27 261
261 26
26 24
24 23
23 22
22 221
221 21
21 Turns a Datasette instance into a ChatGPT plugin to interrogate your data.21
Turns a Datasette instance into a ChatGPT plugin to interrogate your data.21 21
21 Conversational AI Data Analyst: Simplifying Reporting, Amplifying Insights211
Conversational AI Data Analyst: Simplifying Reporting, Amplifying Insights211 18
18 18
18 18
18 17
17 17
17 17
17 17
17 16
16 16
16 16
16 16
16 16
16 15
15 15
15 15
15 15
15 14
14 14
14 14
14 13
13 13
13 13
13 13
13 13
13 12
12 12
12 12
12 121
121 12
12 Unlock the potential of your data with Dxyfer's AI-based augmented intelligence tools.12
Unlock the potential of your data with Dxyfer's AI-based augmented intelligence tools.12 12
12 11
11 11
11 11
11 11
11 10
10 10
10 10
10 101
101 10
10 10
10 9
9 91
91 9
9 9
9 9
9 9
9 9
9 9
9 8
8 8
8 8
8