
Overview
Developed by Google Research, Lumiere is a cutting-edge space-time diffusion model designed specifically for video generation. Lumiere focuses on synthesizing videos that portray realistic, diverse, and coherent motion.
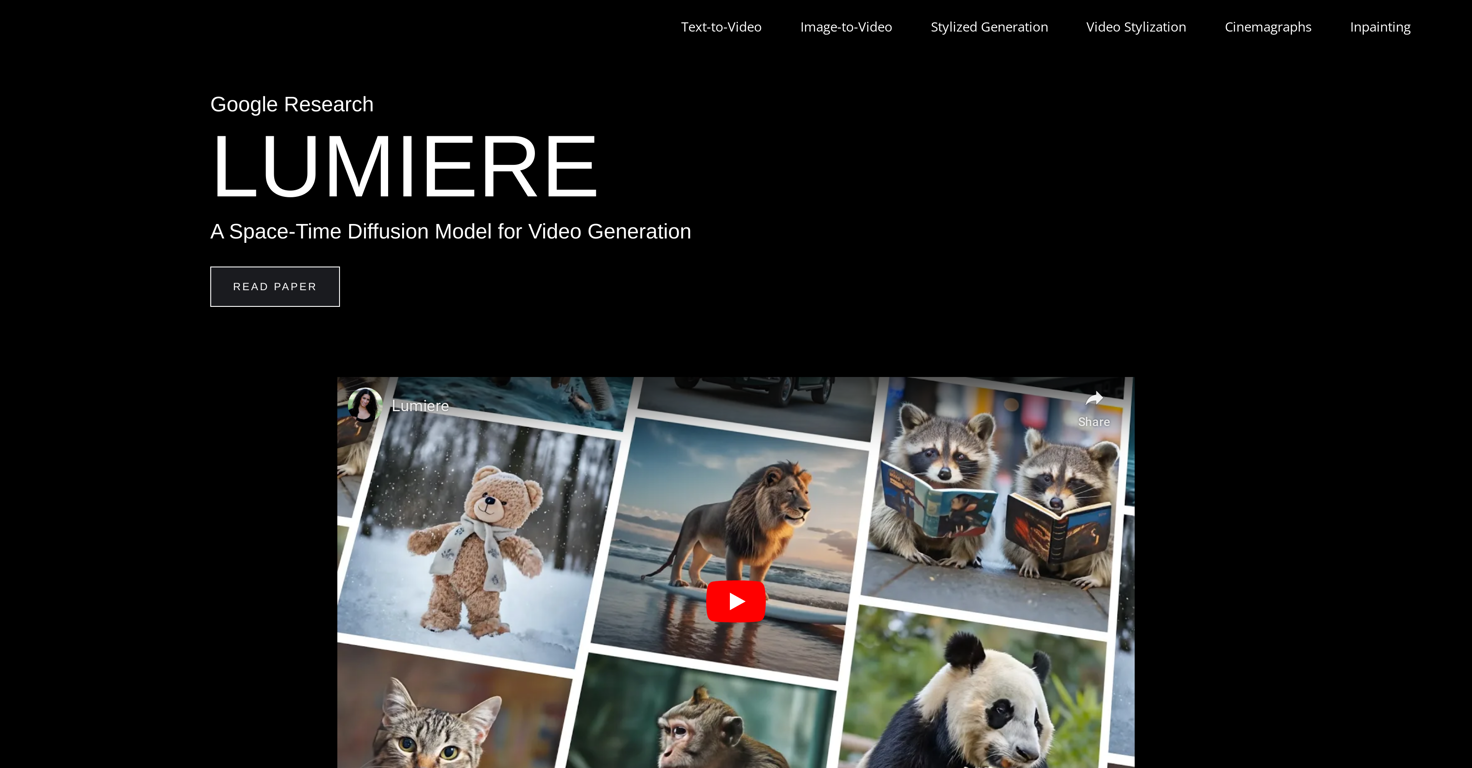
It has three distinct functionalities: Text-to-Video, Image-to-Video, and Stylized Generation. In the Text-to-Video feature, Lumiere generates videos based on text inputs or prompts, presenting a dynamic interpretation of the input.
The Image-to-Video feature works similarly, using an input image as a starting point for video generation.Lumieres Stylized Generation capability gives unique styles to the generated video, using a single reference image.
This allows Lumiere to create videos in the target style by utilizing fine-tuned text-to-image model weights. Notably, Lumiere uses a distinctive Space-Time U-Net architecture that enables it to generate an entire video in one pass.
This is in contrast to many existing video models, which first create keyframes and then perform temporal super-resolution, a process which can compromise the temporal consistency of the video.Finally, Lumieres application extends to various scenes and subjects, like animals, nature scenes, objects, and people, often portraying them in novel or fantastical situations.
Lumiere has potential applications in entertainment, gaming, virtual reality, advertising, and anywhere else dynamic and responsive visual content is needed.
Releases

Pricing
Top alternatives
-
 Turn Music & Ideas into Viral Videos In One Click
Turn Music & Ideas into Viral Videos In One Click kanawati🙏 1,152 karmaMar 26, 2025@freebeat AIThe concept is great.
kanawati🙏 1,152 karmaMar 26, 2025@freebeat AIThe concept is great. -
 Create AI-generated videos with easeWE USE D-ID AT THE COLORADO VIRTUAL CREATIVE FACTORY...AND LOVE IT.
Create AI-generated videos with easeWE USE D-ID AT THE COLORADO VIRTUAL CREATIVE FACTORY...AND LOVE IT. -
 Transform text into captivating videos instantly.You get 300 credits upon signing up, which is enough to test out the app and see its potential. I had a bit of fun with it. It takes a few minutes to generate content, but the results are impressive. There are many styles, modifiers, and customization options available. I would definitely use this for content creation or storytelling.
Transform text into captivating videos instantly.You get 300 credits upon signing up, which is enough to test out the app and see its potential. I had a bit of fun with it. It takes a few minutes to generate content, but the results are impressive. There are many styles, modifiers, and customization options available. I would definitely use this for content creation or storytelling. -
 Create AI spokesperson videos from text
Create AI spokesperson videos from text -
 AI Video GenerationThey're dreaming if they think I'd give them my credit card info just for a free trial. Most useless thing ever...
AI Video GenerationThey're dreaming if they think I'd give them my credit card info just for a free trial. Most useless thing ever... -
 Multi-shot video generation from text and image.
Multi-shot video generation from text and image.










