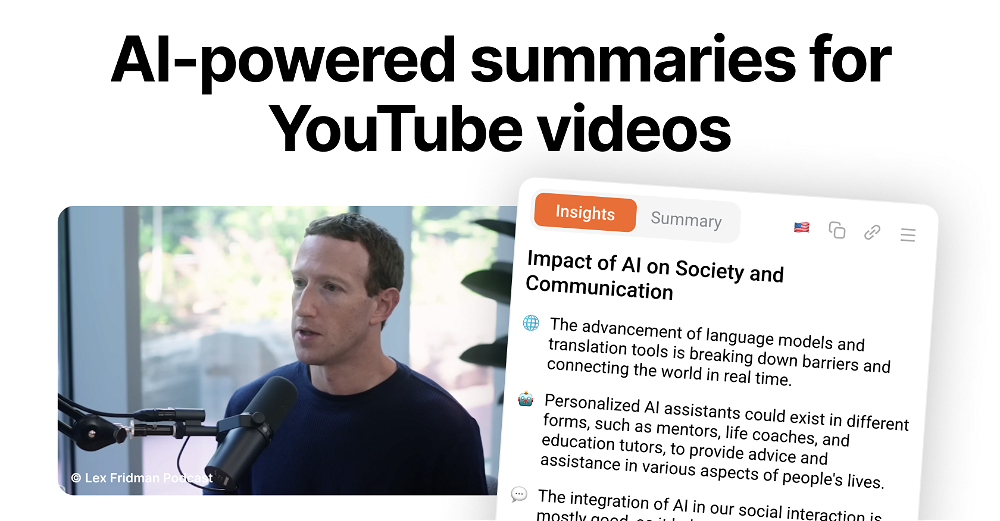
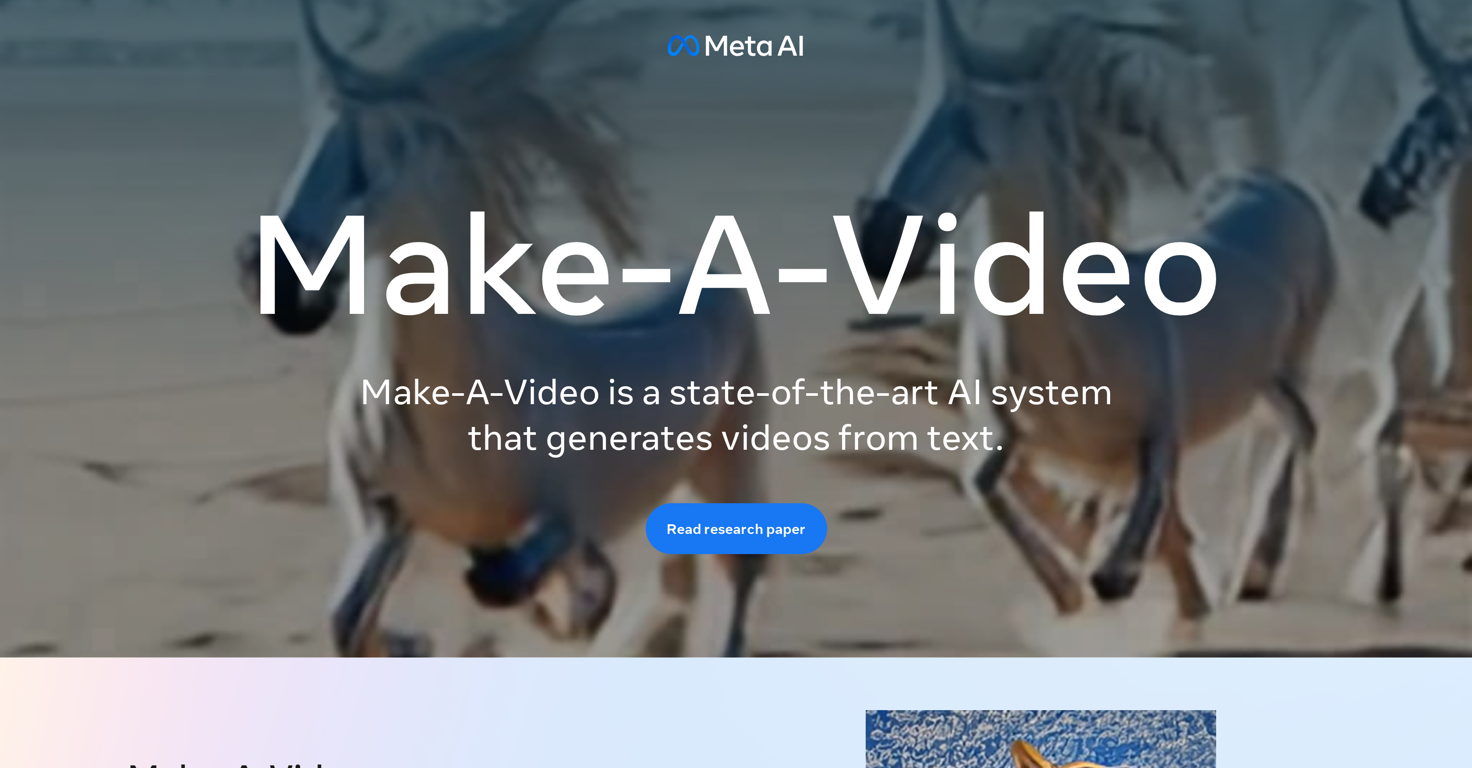
What is Make-A-Video?
Make-A-Video is a state-of-the-art AI system developed by Meta AI. It enables users to generate unique and high-quality videos from text prompts. Users have the option to create videos ranging from surreal to realistic. It's currently undergoing internal testing and development but is expected to be available to the public soon.
How does Make-A-Video work?
Make-A-Video works by combining text-to-image generation technology with the ability to learn from unlabeled videos. It uses images with descriptors to understand world appearance and unlabeled videos to learn how the world moves. Given a few words or lines of text, Make-A-Video can create unique, whimsical videos.
Can Make-A-Video add motion to single images?
Yes, Make-A-Video can add motion to a single image. The system has progressed from generating static images to creating videos filled with motion from a single image or a pair of images.
Can I create variations of an initial video with Make-A-Video?
Yes, one of the features of Make-A-Video is the ability for users to create variations of an original video, thereby expanding creative possibilities.
What steps are Meta AI taking to prevent the generation of harmful content with Make-A-Video?
Meta AI is taking numerous steps to prevent the generation of harmful content with Make-A-Video. They analyze millions of pieces of data and apply filters to reduce the potential for harmful content surfacing in videos. Additionally, they add watermarks to their videos to indicate they are AI-generated, and not captured video. They are also thorough with testing and iterative improvements to ensure safety and deliberate usage.
Is Make-A-Video better than other video generation tools?
Make-A-Video is designed to outperform previous tools for video generation. It has been tested and found to be 3 times better at representing text input and 3 times higher in quality compared to the previous state of the art.
Is there a way to distinguish content created using Make-A-Video?
Yes, to indicate AI-generated content and distinguish it from captured videos, Make-A-Video adds a watermark to all the videos it generates.
When can I expect to use Make-A-Video?
While there isn't a specific release date, Make-A-Video is currently in the internal testing and development phase and is expected to be released to the public in the near future.
Can I generate multiple versions of the same video using Make-A-Video?
Yes, Make-A-Video allows users to generate multiple variations of the same video, thus offering diverse creative possibilities.
Can Make-A-Video fill in the motion between two images?
Absolutely. Make-A-Video can not only add motion to a single image but also fill-in the between motion of two images, converting what was static into dynamic video content.
How realistic can the videos generated by Make-A-Video be?
With Make-A-Video, the realistic quality of the videos can be as high as the user desires. From whimsical and surreal to realistic and stylized, Make-A-Video has the ability to generate a range of video outputs.
Does Make-A-Video create videos directly from text prompts?
Indeed, Make-A-Video creates videos directly from text prompts. Users input a few words or lines of text and Make-A-Video generates distinctive, high-quality videos based on those prompts.
What is Meta AI doing to develop responsible AI through Make-A-Video?
Meta AI is committed to the responsible development and use of AI through Make-A-Video. They take various steps to reduce the creation of harmful, biased, or misleading content, like adding a watermark to all generated videos to signify they are AI-created, and not real-world captured videos. Research has been carried out to test and iteratively improve upon this technology to ensure it's safe and intentional usage.
Can Make-A-Video learn world motion from unlabeled videos?
Yes, Make-A-Video learns world motion from unlabeled videos. This information helps the system to more effectively generate videos that accurately depict movement within the world.
How does Make-A-Video use text-to-image generation technology?
Make-A-Video uses text-to-image generation technology to create its videos. Users input a few words or lines of text, and Make-A-Video uses those prompts to generate videos. The system learns about the world's appearance using images with descriptors and how it typically moves using unlabeled videos.
Can Make-A-Video turn static images into motion videos?
Exactly, Make-A-Video can turn static images into motion videos. It takes a single image or a pair and imbues them with motion, effectively creating dynamic video output.
Is Make-A-Video's video creation process considered state-of-the-art?
Yes, Make-A-Video's video creation process is indeed considered state-of-the-art. It accurately represents text input and has been found to be three times higher in quality compared to previous video generation technologies.
What's the quality of videos created by Make-A-Video compared to its previous versions?
The quality of videos created by Make-A-Video is far superior compared to its previous versions. According to user studies, it offers a 3x better representation of textual input and 3x improved video quality.
How does Make-A-Video understand world appearance?
Make-A-Video understands world appearance by employing images with descriptions. By studying and learning from these descriptors, the system comprehends how the world looks and how it is often described.
Is Make-A-Video currently publicly available?
No, Make-A-Video is not currently publicly available. It's still undergoing internal testing and development but is expected to be released to the public soon.


 3,40329
3,40329 5893
5893 5283
5283 4974
4974 4213
4213 3962
3962 2813
2813 2733
2733 219
219 2041
2041 1922
1922 1562
1562 133
133 1143
1143 Transform text and images into high-quality videos instantly with Dream Machine AI.1052
Transform text and images into high-quality videos instantly with Dream Machine AI.1052 103
103 1013
1013 99
99 93
93 881
881 70
70 64
64 551
551 511
511 50
50 50
50 394
394 381
381 38
38 30
30 291
291 29
29 281
281 27
27 26
26 25
25 25
25