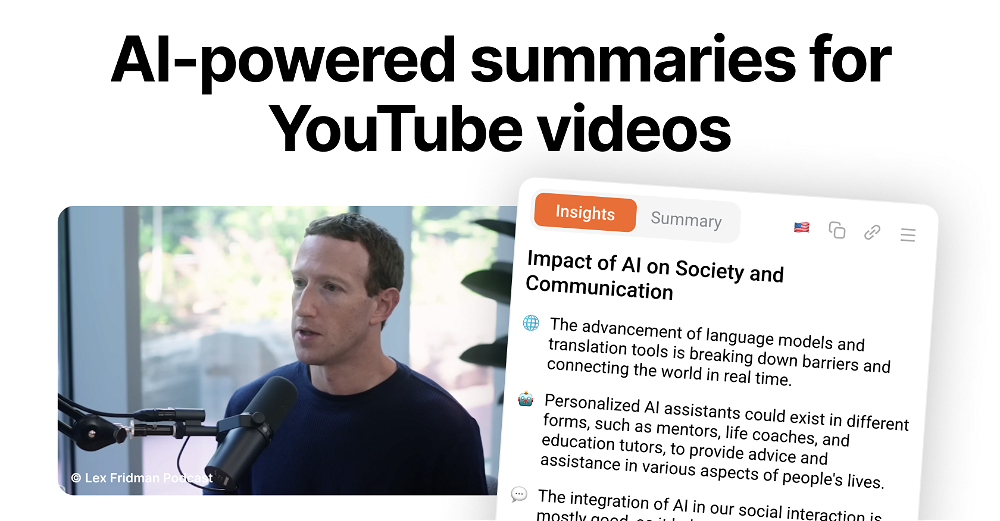
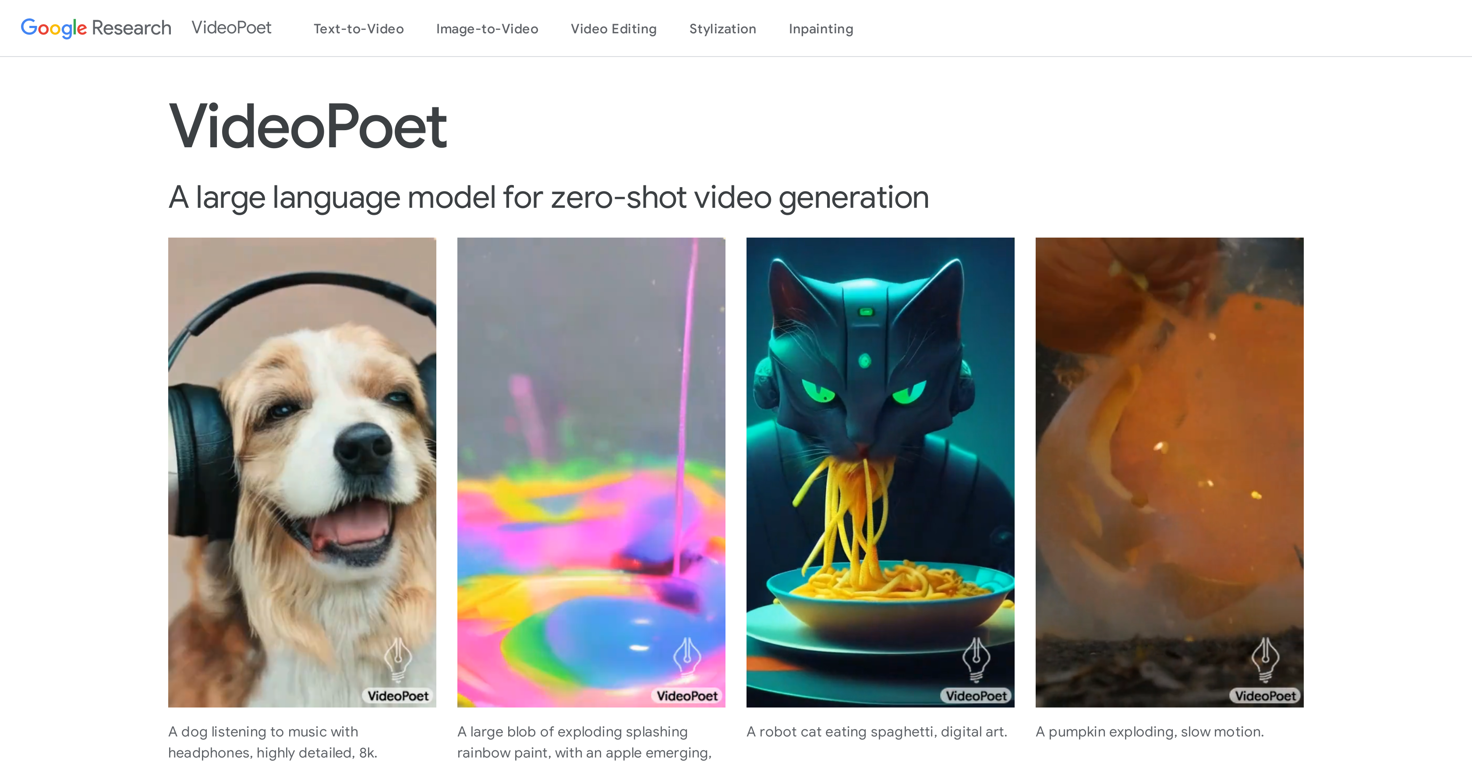
What is VideoPoet?
VideoPoet is a tool developed by Google Research, designed to represent a significant evolution in video generation. It essentially transforms autoregressive language models into a high-quality video generator. VideoPoet is proficient in producing large, interesting, and high-fidelity motions.
How does VideoPoet generate videos using language models?
VideoPoet generates videos by integrating and converting autoregressive language models into the video generation process. It uses components such as the MAGVIT V2 video tokenizer and SoundStream audio tokenizer to transform images, video, and audio clips into a sequence of discrete codes in a unified vocabulary. These codes are combined with text-based language models for integration with other modalities like text. In the process, this technology learns across modalities to predict the next video or audio token in a sequence.
What is the role of MAGVIT V2 video tokenizer in VideoPoet?
MAGVIT V2 video tokenizer plays a key role in VideoPoet by transforming images and video clips into a sequence of discrete codes in a unified vocabulary. The codes transformed by MAGVIT V2 are compatible with text-based language models, thereby facilitating modal integration. Essentially, it forms the video language that the autoregressive model learns and synthesizes.
How does SoundStream audio tokenizer contribute to VideoPoet functionality?
The SoundStream audio tokenizer in VideoPoet is responsible for transforming audio clips into discrete codes, similar to how the MAGVIT V2 video tokenizer works with video. These codes are used along with the codes from images and videos to be processed by the autoregressive language model. Moreover, it supports the generation of audio from a video input, marking a leap in multimodal learning.
Can VideoPoet generate both video and audio?
Yes, VideoPoet has the capability to generate both video and audio. The integrated process allows for the generation of audio from a video input, thus enabling a syncing of both audio and visual aspects of a clip.
What formats or orientations are supported by VideoPoet?
VideoPoet can generate videos in both square orientation and portrait. These formats particularly cater to the demands of short-form content, offering flexible options to cater to specific requirements.
Can you edit videos with VideoPoet?
Yes, videos can be edited using VideoPoet. The integrated language model allows for the synthesis and editing of videos with a high degree of temporal consistency. It further provides an array of features like video inpainting and outpainting, and video stylization.
How does VideoPoet ensure temporal consistency in videos?
VideoPoet employs the use of an autoregressive language model that learns across different modalities such as video, image, audio, and text to ensure temporal consistency in videos. This allows for autoregressive prediction of the next video or audio token in a sequence, thus maintaining continuity and consistency throughout the video.
What are some examples of multimodal learning objectives in VideoPoet's training framework?
In the training framework of VideoPoet, there are multiple multimodal generative learning objectives incorporated that include tasks like text-to-video, text-to-image, image-to-video, video frame continuation, video inpainting and outpainting, video stylization, and even video-to-audio.
How is the autoregressive functionality used in VideoPoet?
The autoregressive functionality within VideoPoet is used to learn across various modalities such as video, image, audio, and text to autoregressively predict the next video or audio token in the sequence. This learning approach is instrumental in synthesizing and editing videos with a high degree of temporal consistency.
What is the process of converting text-to-video in VideoPoet?
The text-to-video conversion in VideoPoet is facilitated by an integration of the provided text with the learnt sequence of discrete codes from the images and audio clips. By predicting the next token in the sequence based on the text input, VideoPoet creates a video that aligns with the narrative framework provided by the text description.
Can you use VideoPoet to convert image-to-video?
Yes, VideoPoet does have the capability to convert image-to-video. It uses discrete codes from an input image to convert into a sequential video. The autoregressive language model then pieces these codes into a consistent video sequence.
Can you change the style of a video using VideoPoet?
Yes, VideoPoet can be used to change the style of a video. It combines multimodal learning objectives in the training framework, including stylization. This results in the alteration of existing video styles or application of new styles to create aesthetically desirable videos.
How does text-to-audio feature work in VideoPoet?
VideoPoet's text-to-audio feature works by predicting the next audio token in the sequence based on the text input. It processes the text input through the autoregressive model, leveraging the learnt sequence of discrete codes from audio clips to form a consistent audio narrative that aligns with the text.
What is the aspect ratio of videos generated through VideoPoet?
VideoPoet supports generating videos in orientations that cater to short-form content. This includes both square and portrait orientations offering diversity in aspect ratios for end-users.
What is the video generation process in VideoPoet?
The video generation process in VideoPoet functions via learning from autoregressive language models. It employs the MAGVIT V2 video tokenizer and the SoundStream audio tokenizer to transform inputs from images, videos, and audio clips into sequence of discrete codes. Then, it merges these codes with text-based language models to predict the next video or audio token in a sequence that eventually forms a high-quality video.
What is the operational sequence of VideoPoet?
The operational sequence of VideoPoet involves the conversion of inputs (images, video, audio clips and text) into discrete codes, integration with text-based language models, and autoregressive prediction. Once the sequence of codes is generated and integrated, the autoregressive language model is set to work to predict the next video or audio token, thus synthesizing a complete video.
How does VideoPoet handle multiple video-centric inputs and outputs?
VideoPoet is designed to multitask on multiple video-centric inputs and outputs. This feature is achieved through the tool’s unique ability to learn across different modalities, including text, audio, video, and image, thus enabling the generation of multiple outputs selectively or simultaneously.
What kind of languages does VideoPoet support?
The language models that VideoPoet utilizes to generate videos are autoregressive. While specific languages are not defined on their website, this tool is typically designed to understand and process human languages, which suggests a potential capacity for multi-language support.
What is the output format of VideoPoet generated videos and audios?
The output format of videos and audios generated by VideoPoet isn't explicitly mentioned on their website. However, given that it is a Google Research product specializing in creating high-quality video content, it can be inferred that it supports popular video and audio formats commonly used in digital media.
 3,37529
3,37529 5981
5981 5893
5893 5263
5263 4854
4854 4203
4203 2813
2813 2733
2733 218
218 2021
2021 1912
1912 1562
1562 133
133 1133
1133 103
103 1003
1003 99
99 881
881 Transform text and images into high-quality videos instantly with Dream Machine AI.872
Transform text and images into high-quality videos instantly with Dream Machine AI.872 70
70 64
64 541
541 50
50 49
49 491
491 381
381 384
384 36
36 30
30 291
291 27
27 26
26 26
26 25
25 24
24 24
24