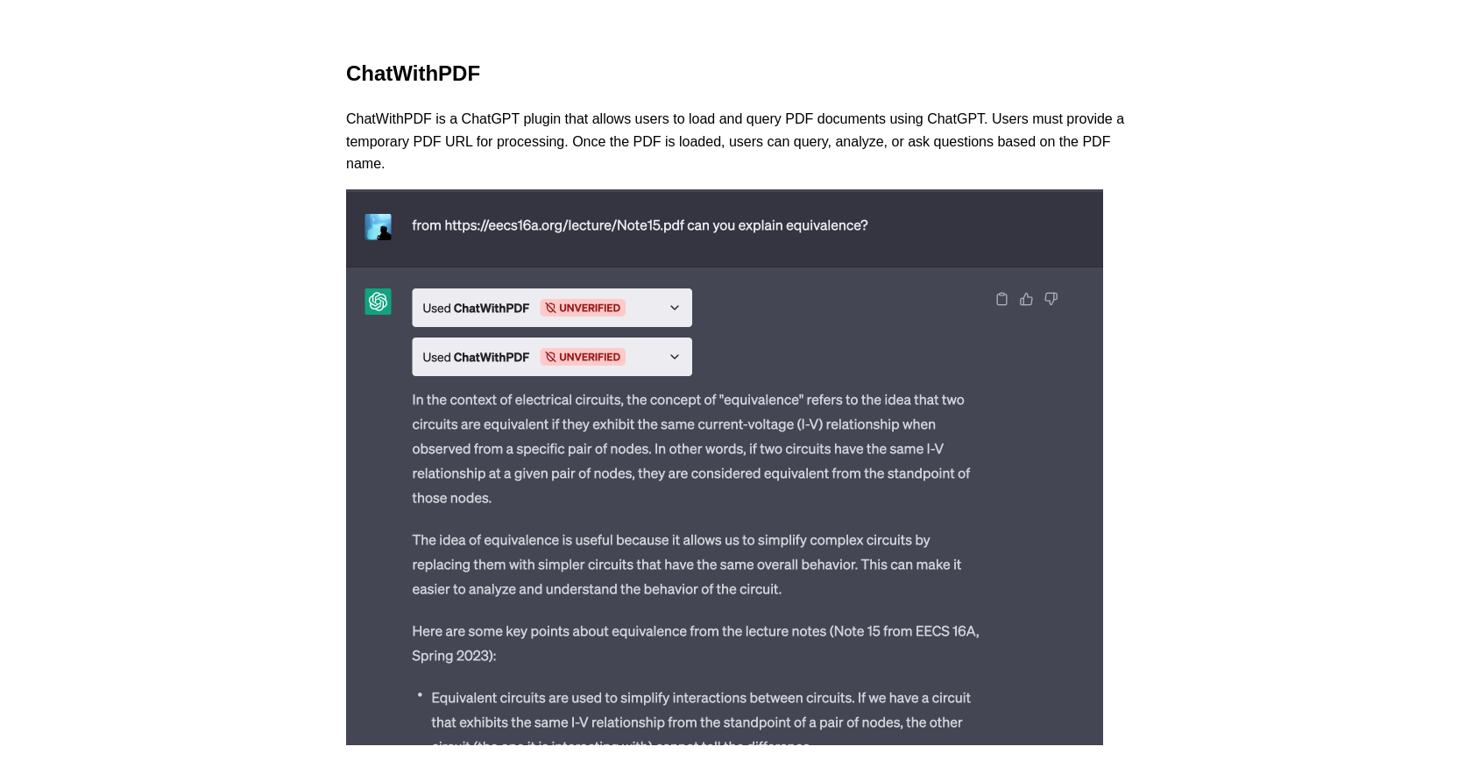
Chatwithpdf is a ChatGPT plugin tool that allows users to load and query PDF documents using ChatGPT. To use the tool, users must provide a temporary PDF URL for processing from which they can query, analyze, or ask questions based on the PDF content.
The tool offers a convenient way to semantically search PDF documents based on user queries and returns relevant matches. The plugin extracts relevant information from the PDF document by processing it and matching the queries with the processed information, all with the aim of returning the most appropriate matches.
To use Chatwithpdf, users need to add it as an unverified plugin in the "Plugin Store" of the ChatGPT UI. There is no need for installation as it is a web-based tool that is readily available for use.
The tool does not intentionally store any data permanently, and all PDFs are embedded and immediately wiped. Embeddings are stored with ChromaDB on the same deployment server and wiped with each new deployment.
The key features of Chatwithpdf include the ability to process and semantically search PDF documents, extract relevant information from the document based on user queries, and load and process PDF documents from a temporary URL.
The tool is useful for users who need to quickly extract relevant information from PDF documents and seek a tool that offers a seamless experience.
How would you rate ChatWithPDF?
Help other people by letting them know if this AI was useful.

Feature requests

100 alternatives to ChatWithPDF for Document Q&A
-
 8965
8965 -
 5866
5866 -
 403
403 -
 1896
1896 -
 169
169 -
 1513
1513 -
 1332
1332 -
 120
120 -
 116
116 -
 1123
1123 -
 108
108 -
 103
103 -
 1011
1011 -
 871
871 -
 831
831 -
 814
814 -
 75
75 -
 741
741 -
 Private Q&A with your Documents on Windows or Mac.72
Private Q&A with your Documents on Windows or Mac.72 -
 69
69 -
 64
64 -
 641
641 -
 Remember everything. Query all your documents, media, and knowledge with AI.631
Remember everything. Query all your documents, media, and knowledge with AI.631 -
 611
611 -
 592
592 -
 58
58 -
 572
572 -
 56
56 -
 482
482 -
 47
47 -
 479
479 -
 46
46 -
 403
403 -
 39
39 -
 38
38 -
 351
351 -
 34
34 -
 34
34 -
 34
34 -
 34
34 -
 33
33 -
 30
30 -
 30
30 -
 301
301 -
 291
291 -
 29
29 -
 29
29 -
 282
282 -
 262
262 -
 26
26 -
 24
24 -
 234
234 -
 23
23 -
 21
21 -
 21
21 -
 21
21 -
 21
21 -
 21
21 -
 20
20 -
 19
19 -
 19
19 -
 191
191 -
 191
191 -
 18
18 -
 18
18 -
 182
182 -
 17
17 -
 171
171 -
 17
17 -
 17
17 -
 16
16 -
 16
16 -
 16
16 -
 16
16 -
 15
15 -
 15
15 -
 15
15 -
 15
15 -
 15
15 -
 14
14 -
 13
13 -
 13
13 -
 13
13 -
 12
12 -
 12
12 -
 12
12 -
 11
11 -
 11
11 -
 10
10 -
 10
10 -
 10
10 -
10
-
 9
9 -
 9
9 -
 9
9 -
 9
9 -
 9
9 -
 9
9 -
 8
8 -
 8
8






Pros and Cons
Pros
Cons
Q&A
If you liked ChatWithPDF
Featured matches
Other matches

Subscribe to our exclusive newsletter, coming out 3 times per week with the latest AI tools. Join over 470,000 readers.
Help
To prevent spam, some actions require being signed in. It's free and only takes a few seconds.
Sign in with Google

